
👨🏻💻 About Me
Hi, I am Xiaokun Feng (丰效坤)! I’m a Ph.D. student at Institute of Automation, Chinese Academy of Sciences (CASIA), supervised by Prof. Kaiqi Huang (IAPR Fellow). Additionally, I’m a member of Visual Intelligence Interest Group (VIIG).
Currently, my research focuses on video multimodal tracking, video generation and world modeling tasks. If you are intrigued by my work or wish to collaborate, feel free to reach out to me.
🔥 News
- 2026.05: 📝One paper (MIGA) on infinite-frame long video generation has been accepted by International Conference on Machine Learning (ICML, CCF-A Conference).
- 2026.02:: 📝One text-conditioned MeanFlow generation work has been accepted by the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR, CCF-A Conference).
- 2026.01:: 📝Two papers (NarrLV and $S^2$-Guidance) have been accepted by the 14th International Conference on Learning Representations (ICLR, CCF-A Conference).
- 2025.09:: 📝Two papers (Omni-effects and ImagerySearch) have been accepted by the 40th Annual AAAI Conference on Artificial Intelligence (AAAI, CCF-A Conference).
- 2025.09: 📝One co-first author paper (CoS) has been accepted by the 39th Conference on Neural Information Processing Systems (NeurIPS, CCF-A Conference).
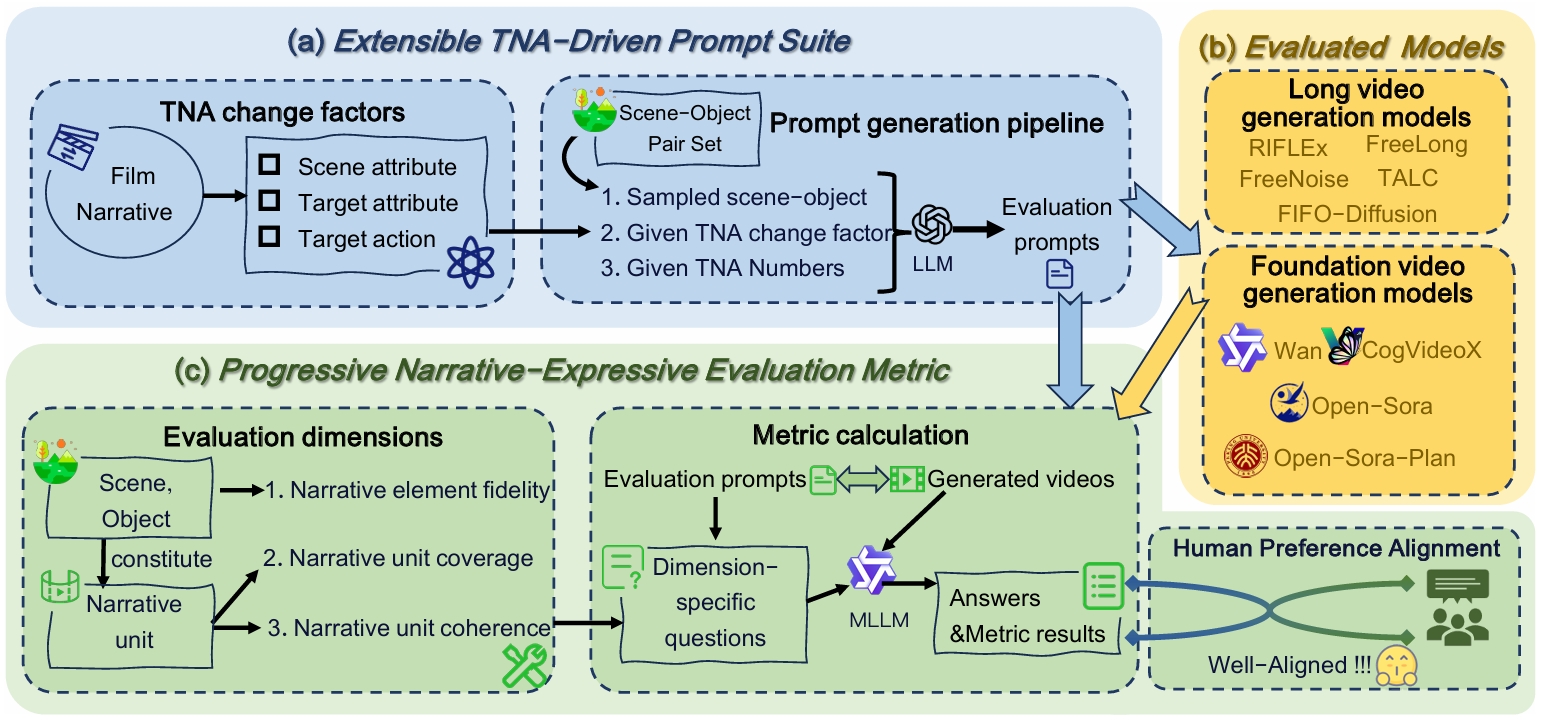
- 2025.08: 📣Our new benchmark (NarrLV) is now available! It is a novel benchmark to evaluate long video generation models from the perspective of narrative expressiveness.
- 2025.06: 📝Two papers (ATCTrack, VMBench) have been accepted by International Conference on Computer Vision (ICCV, CCF-A conference). ATCTrack was recognized as a Highlight paper.
- 2025.05: 📝One paper (CSTrack) has been accepted by International Conference on Machine Learning (ICML, CCF-A conference).
- 2025.01: 📝One paper (CTVLT) has been accepted by IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP, CCF-B conference).
- 2024.09: 📝Two papers (MemVLT and CPDTrack) have been accepted by Conference on Neural Information Processing Systems (NeurIPS, CCF-A Conference).
- 2024.05: 📝One paper (LKRobust) has been accepted by International Conference on Machine Learning (ICML, CCF-A conference).
- 2024.04: 📣 We will present our work (Global Instance Tracking) at TPAMI2023 during the VALSE2024 poster session (May 2024, Chongqing, China) and extend a warm invitation to colleagues interested in visual object/language tracking, evaluation methodologies, and human-computer interaction to engage in discussions with us (see our Poster for more information).
- 2024.04: 📝 One paper has been accepted by the 3rd CVPR Workshop on Vision Datasets Understanding and DataCV Challenge as Oral Presentation (CVPRW, Workshop in CCF-A Conference, Oral)!
- 2023.09: 📝 One paper has been accepted by the 37th Conference on Neural Information Processing Systems (NeurIPS, CCF-A Conference, Poster)!
- 2023.08 : 📝One paper (HIST) has been accepted by Chinese Conference on Pattern Recognition and Computer Vision (PRCV, CCF-C conference).
- 2022.04: 🏆 Obtain Beijing Outstanding Graduates (北京市优秀毕业生) !
- 2021.12: 🏆 Obtain China National Scholarship (国家奖学金) (the highest honor for undergraduates in China, awarded to top 1% students of BIT)!
- 2020.12: 🏆 Obtain China National Scholarship (国家奖学金) (the highest honor for undergraduates in China, awarded to top 1% students of BIT)!
🔬 Research Interests
Video multimodal tracking
- Investigating multimodal tracking to address challenges in integrating visual information with auxiliary modalities (e.g., language, heat maps, infrared images, and depth maps), thereby enhancing tracking accuracy.
- Leveraging Large Language Models (LLMs) in conjunction with visual-language tracking to explore human–computer interaction patterns, contributing to the development of more intuitive and user-friendly interaction systems.
- Following the paradigm of unified foundation models by jointly utilizing datasets from multiple modalities to train a single model capable of handling all multimodal tracking tasks.
Video generation and world modeling
- Focusing on long video generation, aiming to improve existing evaluation benchmarks and advance model design in this field.
- Exploring the applications of foundation video generation models in various downstream tasks.
- Developing interactive world models that support long-horizon generation, real-time simulation, strong temporal consistency, and flexible controllability.
📖 Educations

2018.09 - 2022.06, undergraduate study, Ranking 5/381 (1.3%)
School of Information and Electronics
Beijing Institute of Technology, Beijing
💻 Research Experiences
- 2022.09 - Present: Pursuing a Ph.D. degree at Institute of Automation, Chinese Academy of Sciences (CASIA), conducting research on single-object tracking in Visual Intelligence Interest Group (VIIG), initiated and organized by Dr. Shiyu Hu.
📝 Publications
✅ Acceptance

Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
Xiaokun Feng, Jiashu Zhu, Meiqi Wu, et.al
ICML 2026 (CCF-A Conference)
📌 Long Video Generation 📌 Infinite-Frame Autoregressive Generation 📌 Long-term Temporal Consistency

$S^2$-Guidance: Stochastic Self Guidance for Training-Free Enhancement of Diffusion Models
Chubin Chen, Jiashu Zhu, Xiaokun Feng, et.al
ICLR 2026 (CCF-A Conference)
📌 Diffusion Models 📌 Guidance Optimization 📌 Stochastic Sub-Network Techniques
📃 Paper
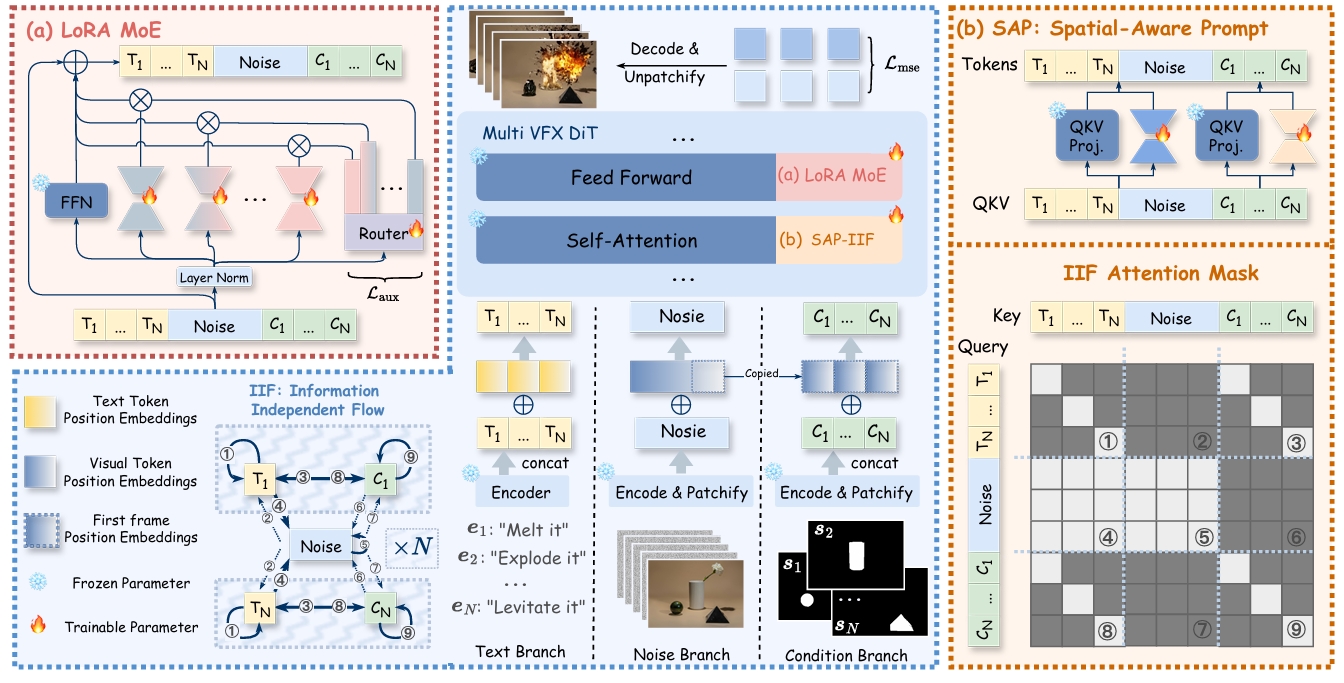
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
Fangyuan Mao, Aiming Hao, Jintao Chen, Dongxia Liu, Xiaokun Feng, et.al
AAAI 2026 (CCF-A Conference)
📌 Visual Effects Generation 📌 Multi-Effect Spatial Control 📌 Prompt-Guided Generation
📃 Paper
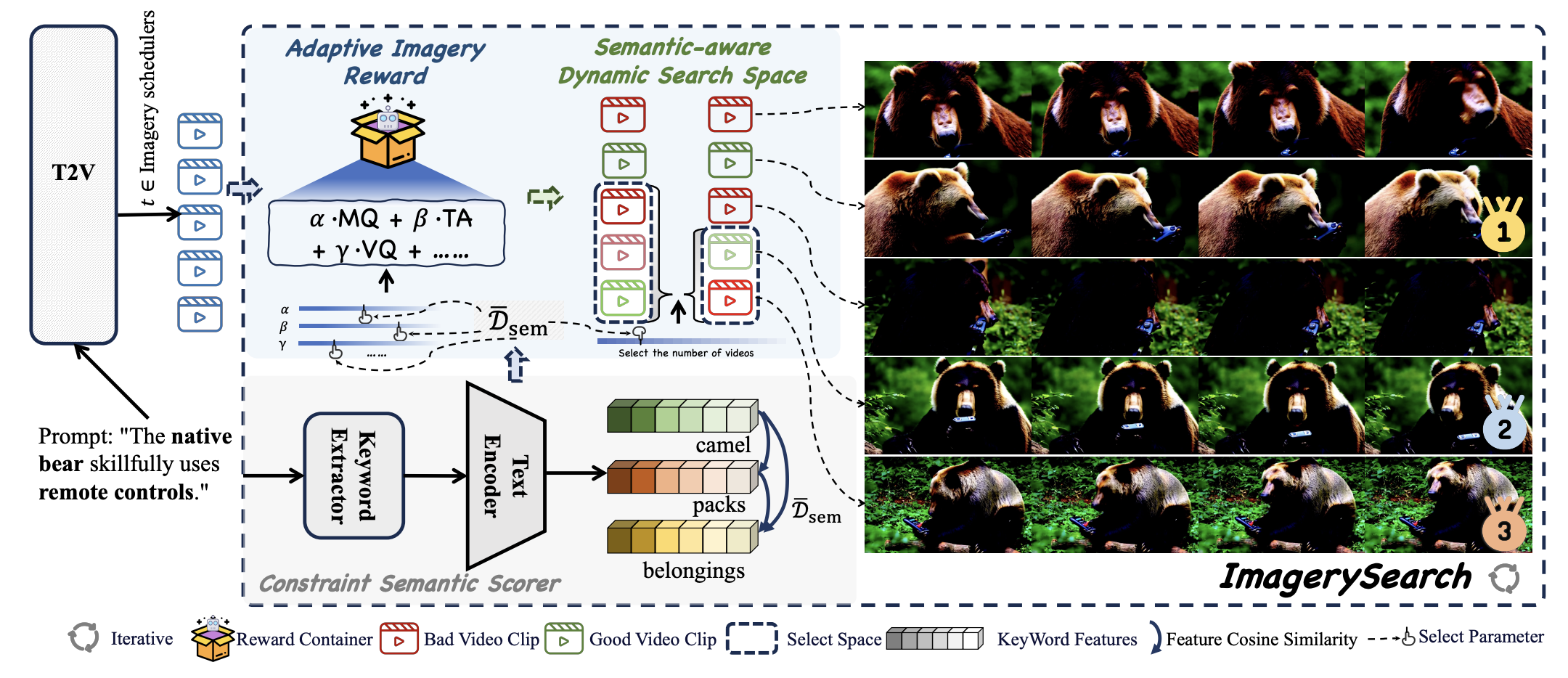
ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
Meiqi Wu, Jiashu Zhu, Xiaokun Feng, et.al
AAAI 2026 (CCF-A Conference)
📌 Visual Effects Generation 📌 Multi-Effect Spatial Control 📌 Prompt-Guided Generation
📃 Paper
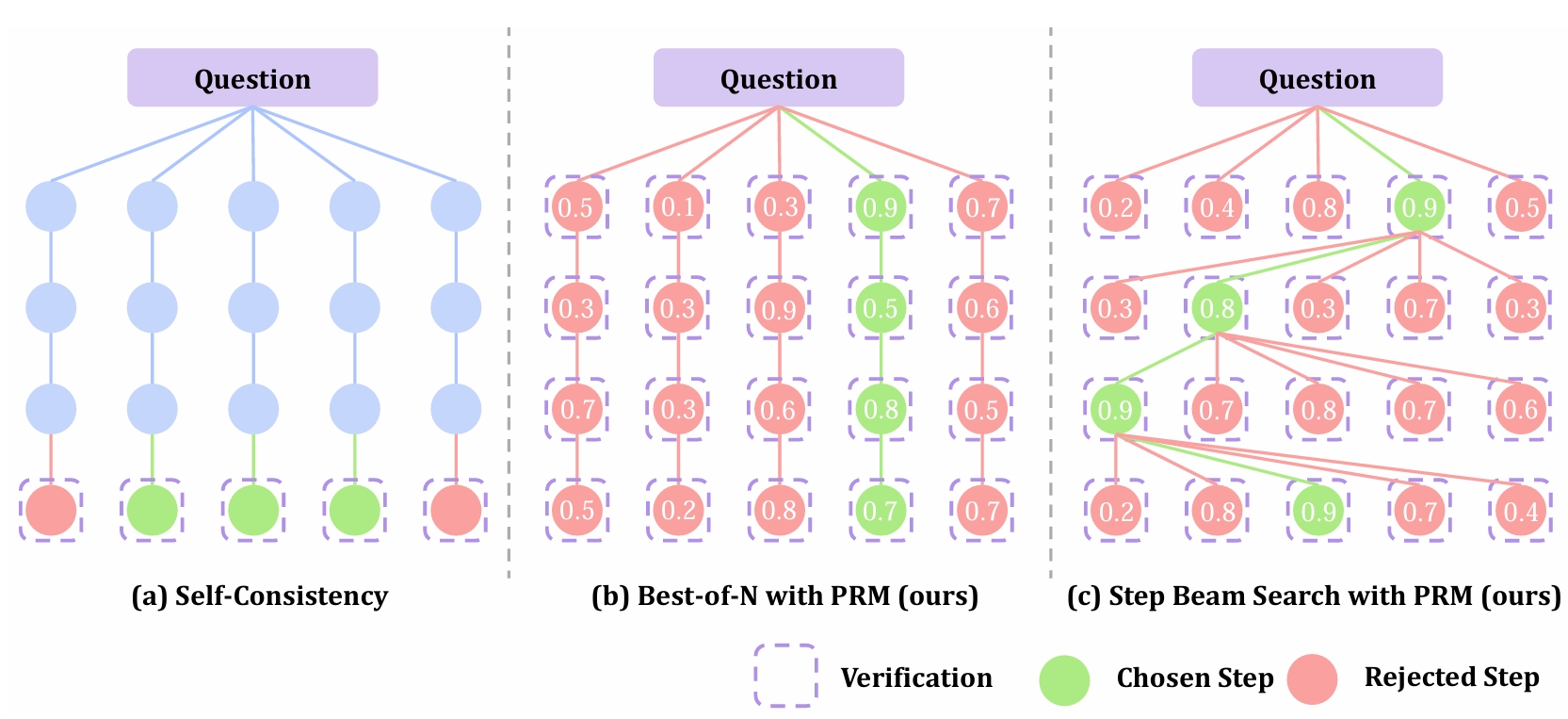
Unveiling Chain of Step Reasoning for Vision-Language Models with Fine-grained Reward
Honghao Chen, Xingzhou Lou, Xiaokun Feng*, et.al
NeurIPS 2025 (CCF-A Conference)
📌 Multimodal Large Language Model 📌 Reinforcement Learning for Reasoning 📌 Process Reward Model
📃 Paper
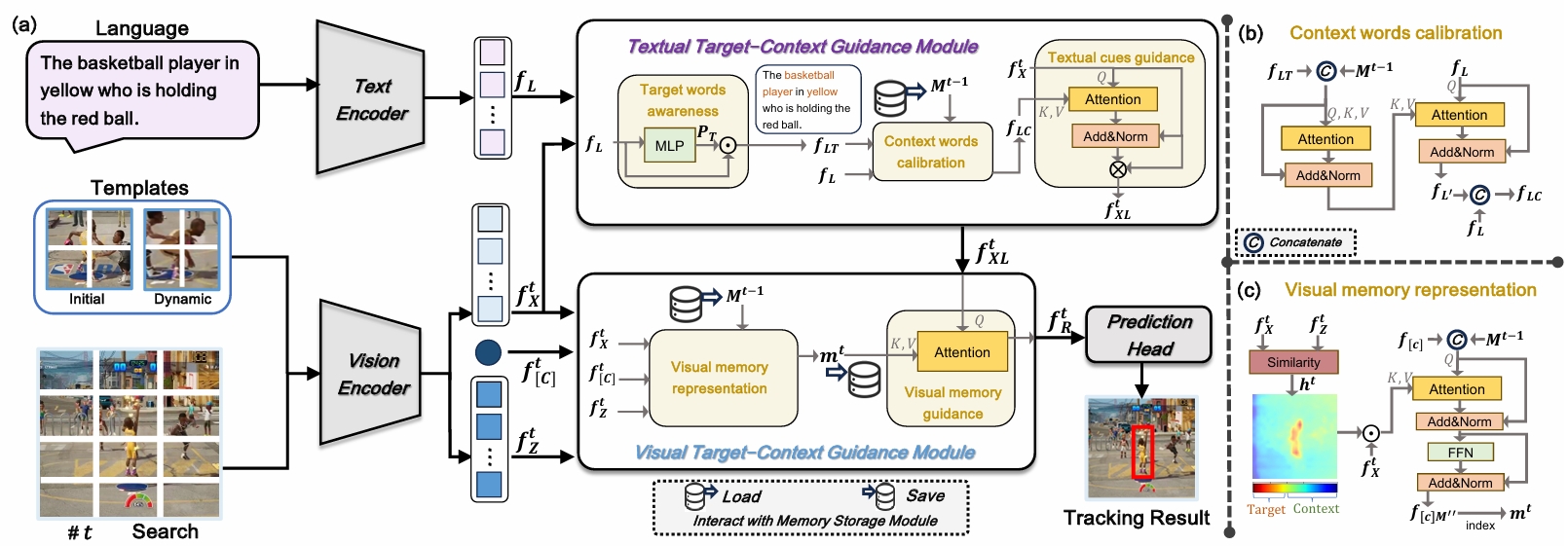
ATCTrack: Aligning Target-Context Cues with Dynamic Target States for Robust Vision-Language Tracking
Xiaokun Feng*, Shiyu, Hu*, Xuchen, Li, DaiLing, Zhang, et.al
ICCV 2025 (CCF-A Conference, Highlight)
📌 Visual Language Tracking 📌 Vision-Language Alignment 📌 Adaptive Prompts
📃 Paper
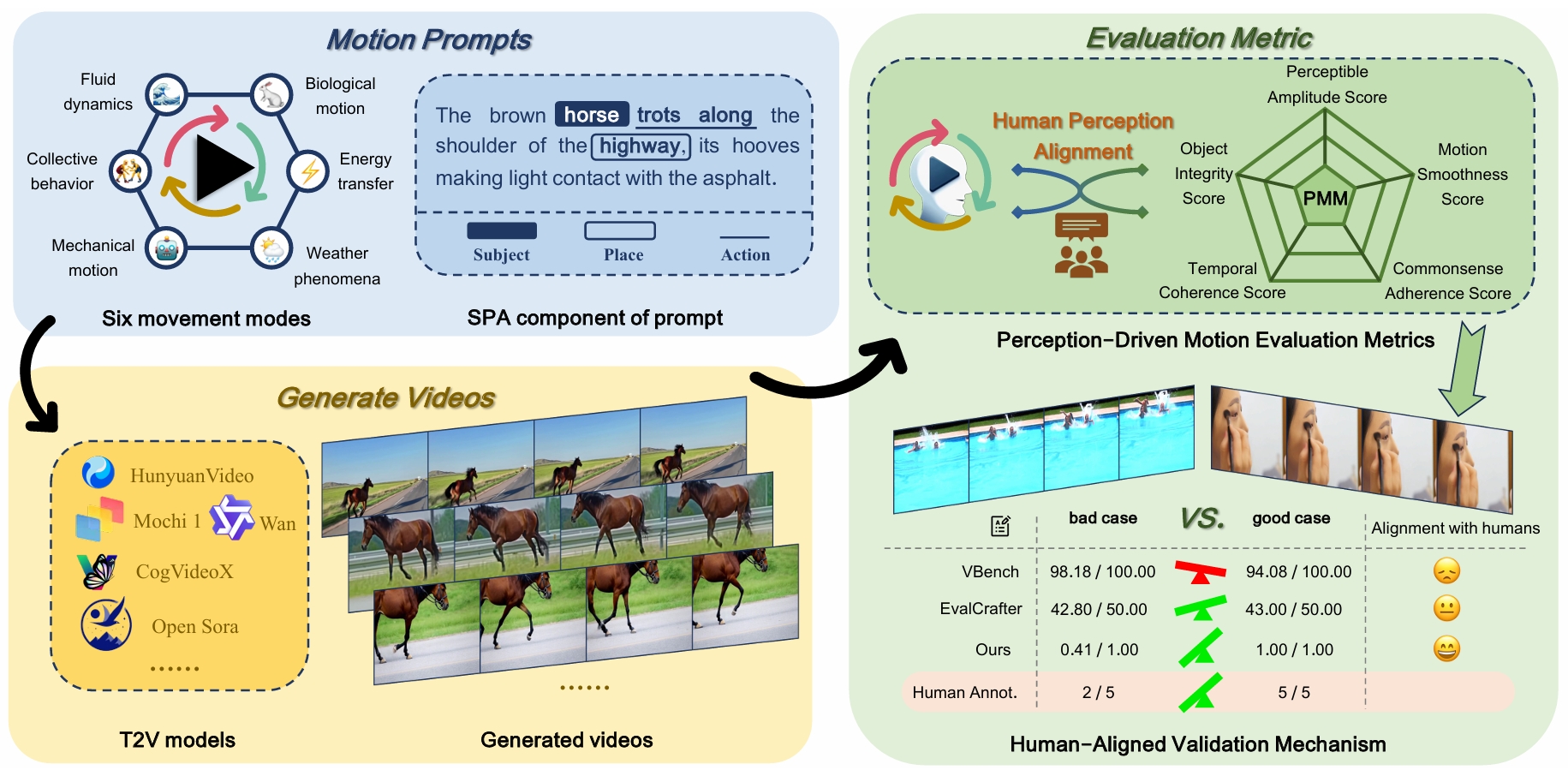
VMBench: A Benchmark for Perception-Aligned Video Motion Generation
Xinran Ling, Chen Zhu, Meiqi Wu, Hangyu Li, Xiaokun Feng*, et.al
ICCV 2025 (CCF-A Conference)
📌 Video Generation 📌 Perception-Aligned Evaluation 📌 Motion Quality Assessment
📃 Paper
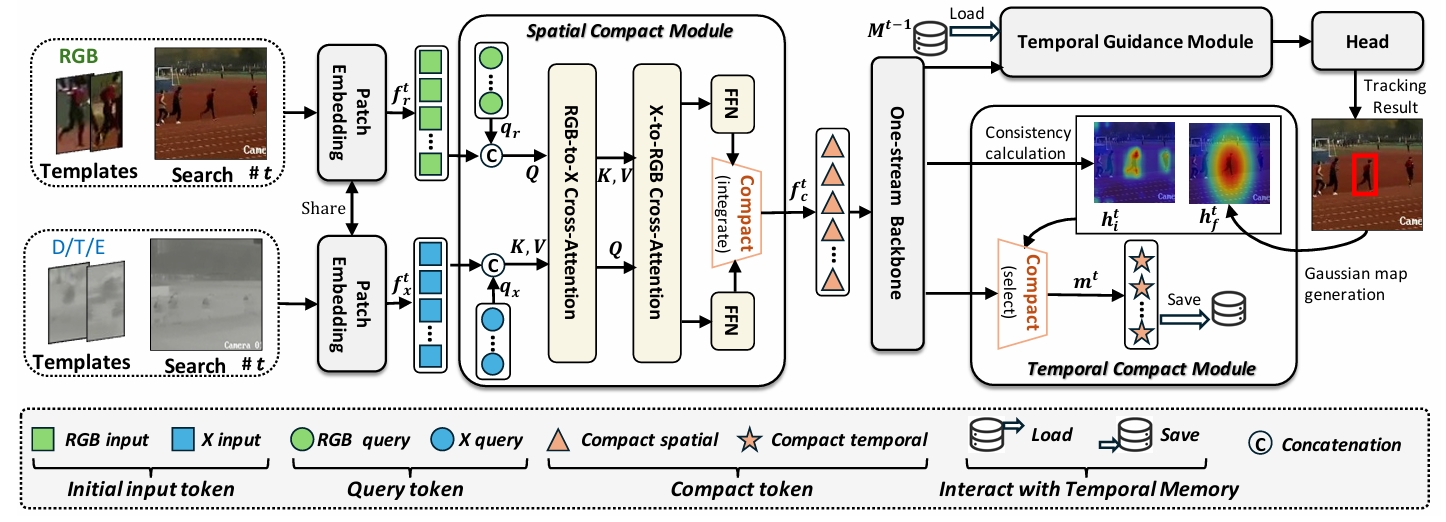
CSTrack: Enhancing RGB-X Tracking via Compact Spatiotemporal Features
Xiaokun Feng*, DaiLing, Zhang, Shiyu, Hu*, et.al
ICML 2025 (CCF-A Conference)
📌 RGB-X Tracking 📌 Foundation Model Design 📌 Compact Spatiotemporal Modeling
📃 Paper
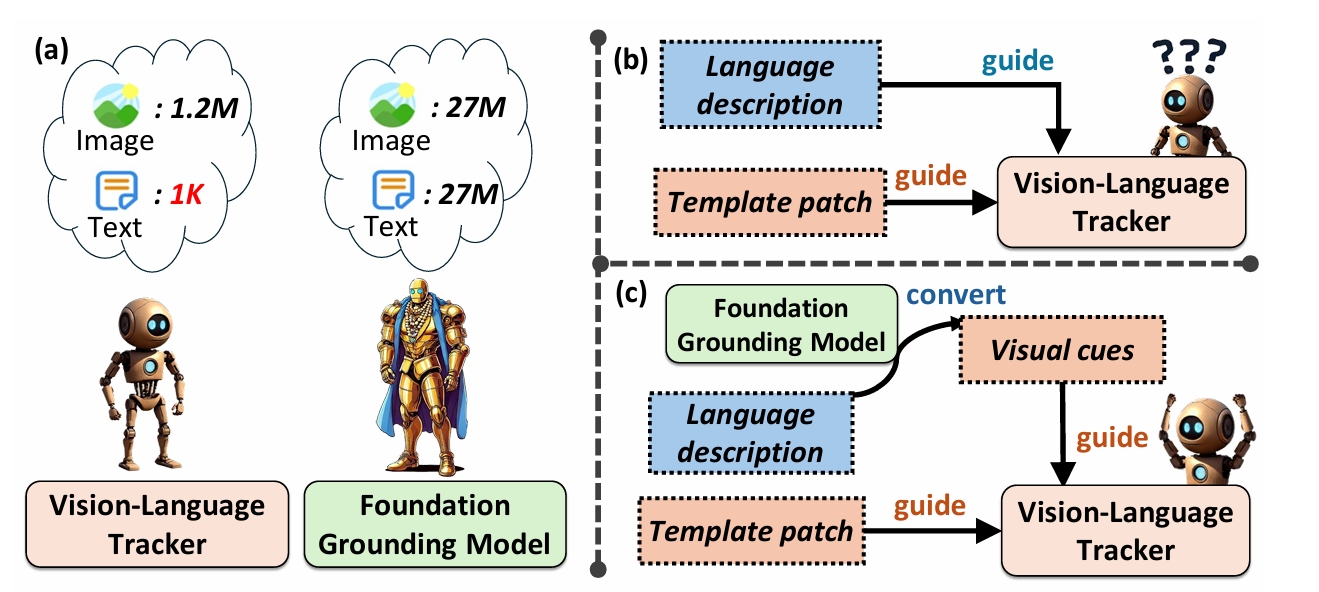
Enhancing Vision-Language Tracking by Effectively Converting Textual Cues into Visual Cues
Xiaokun Feng*, DaiLing, Zhang, Shiyu, Hu*, et.al
ICASSP 2025 (CCF-B Conference)
📌 Visual Language Tracking 📌 Foundation Model 📌 Multimodal Cue Utilization
📃 Paper
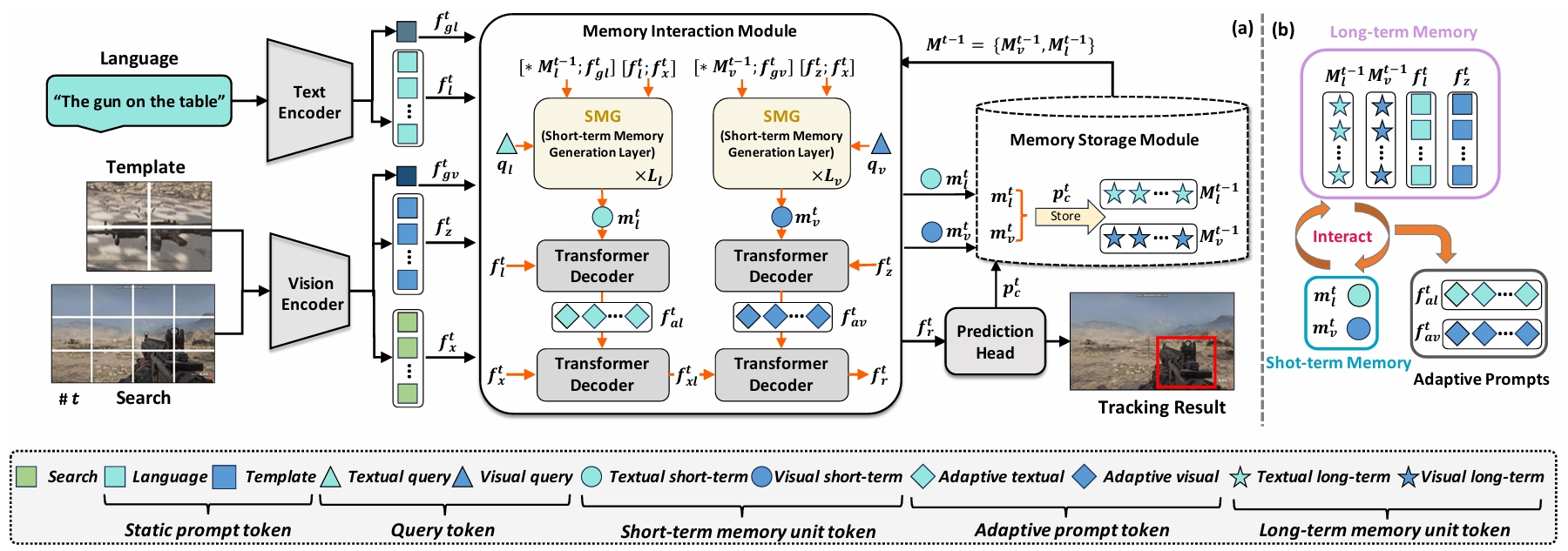
MemVLT: Vision-language tracking with adaptive memory-based prompts
Xiaokun Feng*, Xuchen Li, Shiyu, Hu*, et.al
NeurIPS 2024 (CCF-A Conference)
📌 Visual Language Tracking 📌 Memory-Based Prompt Adaptation 📌 Complementary Learning Systems Theory
📃 Paper
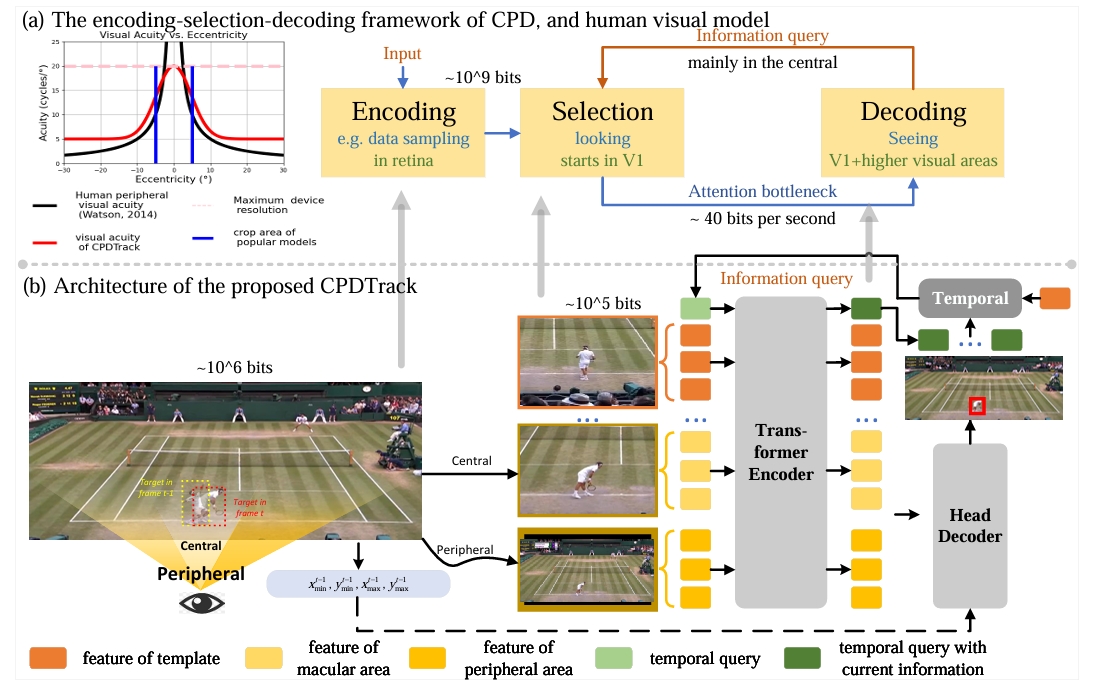
Beyond accuracy: Tracking more like human via visual search
DaiLing, Zhang, Shiyu, Hu*, Xiaokun Feng*, et.al
NeurIPS 2024 (CCF-A Conference)
📌 Human-like Visual Tracking 📌 Central-Peripheral Dichotomy Theory 📌 Spatio-Temporal Discontinuity Challenge
📃 Paper
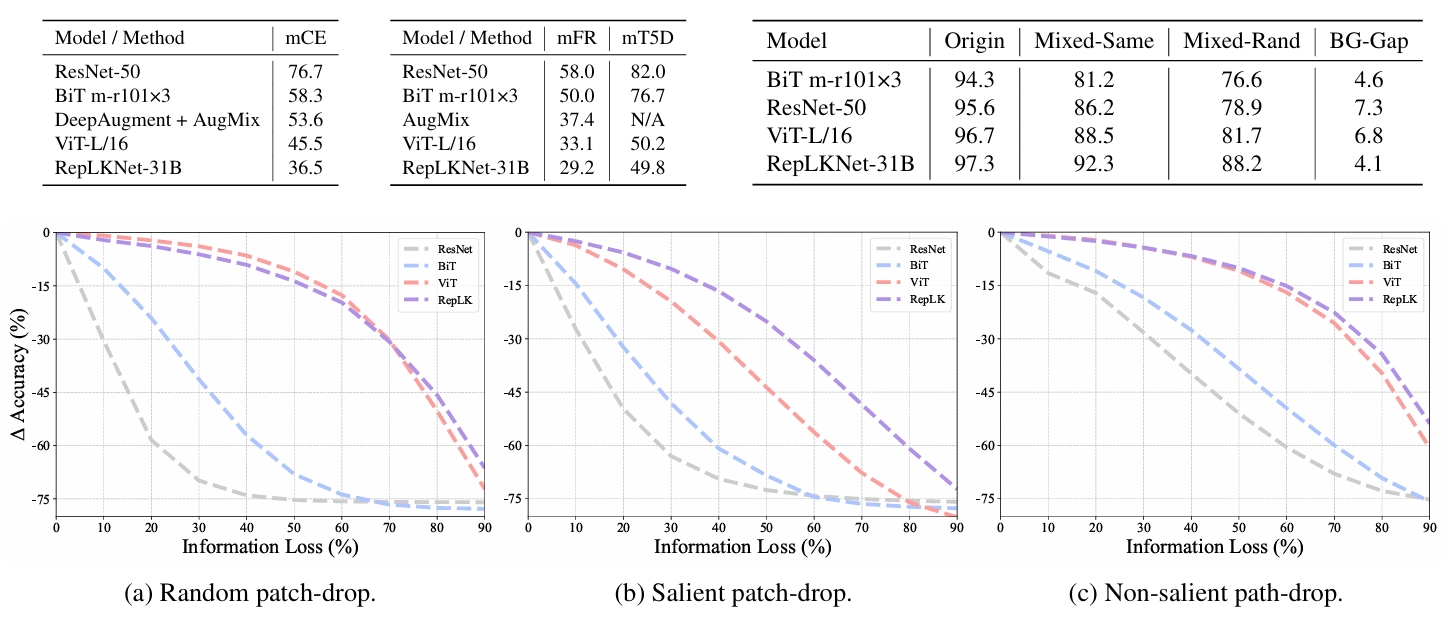
Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness
Honghao Chen, Yurong Zhang, Xiaokun Feng*, et.al
ICML 2024 (CCF-A Conference)
📌 Vision Transformers (ViTs) 📌 Large Kernel Convolutional Networks 📌 Robustness
📃 Paper

DTLLM-VLT: Diverse Text Generation for Visual Language Tracking Based on LLM
Xuchen Li, Xiaokun Feng*, Shiyu Hu, Meiqi Wu, Dailing Zhang, Jing Zhang, Kaiqi Huang
📌 Visual Language Tracking 📌 Large Language Model 📌 Evaluation Technique
📃 Paper
CVPRW 2024 Oral (Workshop in CCF-A Conference, Oral): the 3rd CVPR Workshop on Vision Datasets Understanding and DataCV Challenge

A Multi-modal Global Instance Tracking Benchmark (MGIT): Better Locating Target in Complex Spatio-temporal and Causal Relationship
Shiyu Hu, DaiLing, Zhang, Meiqi Wu, Xiaokun Feng*, et.al
📌 Visual Language Tracking 📌 Long Video Understanding and Reasoning 📌 Hierarchical Semantic Information Annotation
NeurIPS 2023 (CCF-A Conference)
[Paper]
[Slides]
🎖 Honors and Awards
- China National Scholarship (国家奖学金), at BIT, by Ministry of Education of China, 2021
- China National Scholarship (国家奖学金), at BIT, by Ministry of Education of China, 2020
- Beijing Outstanding Graduates (北京市优秀毕业生), at BIT, by Beijing Municipal Education Commission, 2022
- China National Encouragement Scholarship, at BIT, by Ministry of Education of China, 2019
🤝 Collaborators
I am honored to collaborate with these outstanding researchers. We engage in close discussions concerning various fields such as computer vision, AI4Science, and human-computer interaction. If you are also interested in these areas, please feel free to contact me.
- Shiyu Hu, Ph.D. at the Institute of Automation, Chinese Academy of Sciences (CASIA) and University of Chinese Academy of Sciences (UCAS), focusing on visual object tracking, visual language tracking, benchmark construction, intelligent evaluation technique, and AI4Science.
- Meiqi Wu, Ph.D. student at the University of Chinese Academy of Sciences (UCAS), focusing on computer vision, intelligent evaluation technique, and human-computer interaction.
- Xuchen Li, incoming Ph.D. student at the Institute of Automation, Chinese Academy of Sciences (CASIA), focusing on visual object tracking, visual language tracking, and AI4Science.
- Dailing Zhang, Ph.D. student at the Institute of Automation, Chinese Academy of Sciences (CASIA), focusing on visual object tracking, visual language tracking, and AI4Science.
My homepage visitors recorded from April, 2024. Thanks for attention.