Abstract
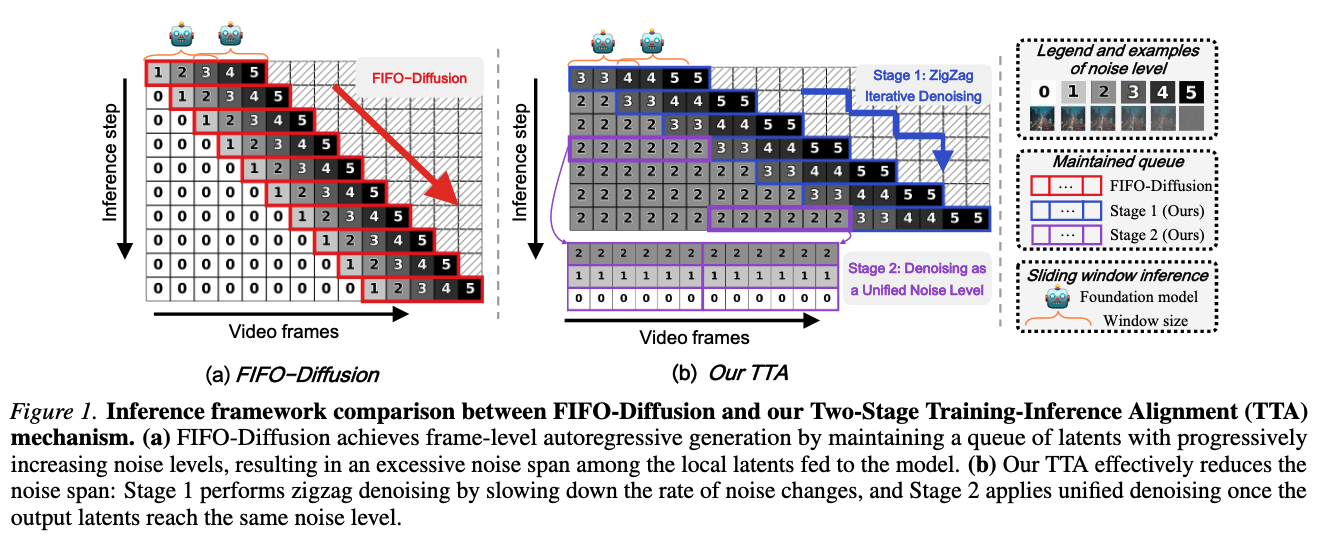
Without incurring significant computational overhead, train-free long video generation aims to enable foundation video generation models to produce longer videos. Frame-level autoregressive frameworks, e.g., FIFO-diffusion, offer the advantage of generating infinitely long videos with constant memory consumption. However, the mismatch between training and inference, coupled with the challenge of maintaining long-term consistency, limits the effective utilization of foundation models.
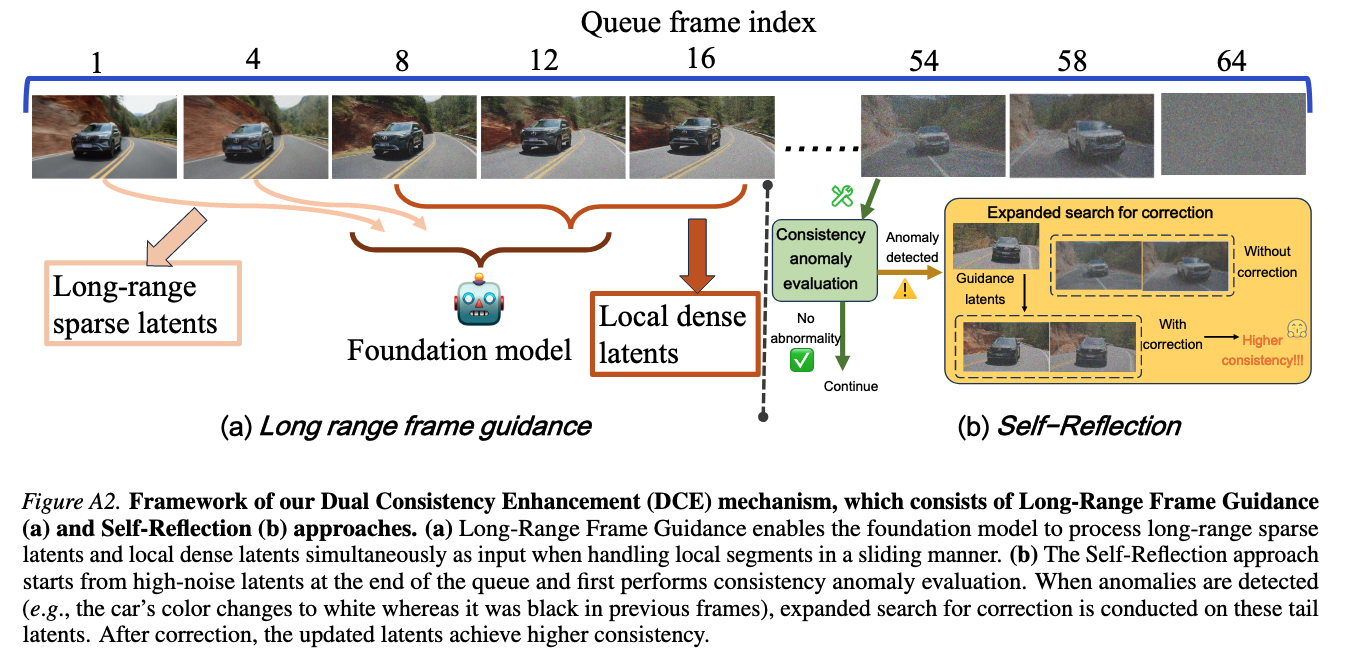
To mitigate these concerns, we propose MIGA, a novel infinite-frame long video generation method. Firstly, we propose an effective two-stage alignment mechanism that mitigates the training-inference gap by reducing the excessive noise span fed to the model. We then introduce an innovative dual consistency enhancement mechanism, where the self-reflection approach corrects early high-noise frames and the long-range frame guidance approach leverages later low-noise frames with broad coverage to steer generation, jointly improving temporal consistency. Extensive experiments on VBench and NarrLV demonstrate the state-of-the-art performance of MIGA.
 Figure A1. MIGA enables temporally consistent, infinite-frame (∞) video generation in a training-free manner. We present three long videos (1000+ frames) generated by MIGA, while the foundation model used by MIGA, Wan2.1-1.3B, supports only 81 frames by default.
Figure A1. MIGA enables temporally consistent, infinite-frame (∞) video generation in a training-free manner. We present three long videos (1000+ frames) generated by MIGA, while the foundation model used by MIGA, Wan2.1-1.3B, supports only 81 frames by default.